filter a stream of documents to
accelerate users filling in knowledge gaps.
KBA ran as an evalution in TREC for three years: 2012, 2013, and 2014. In 2015, it will be succeeded by TREC Dynamic Domain. See TREC KBA overview slides, papers, and truth data here.
KBA 2012 was very exciting: 11 teams submitted 43 runs to solve the CCR task.
KBA 2013 had more tasks and more entities and an even richer stream corpus.
We have completed TREC KBA 2014 with 11 teams and many long-tail entities
The KBA StreamCorpus is described by its home page in s3: http://s3.amazonaws.com/aws-publicdatasets/trec/kba/index.html
Join the TREC KBA discussion forum for updates.
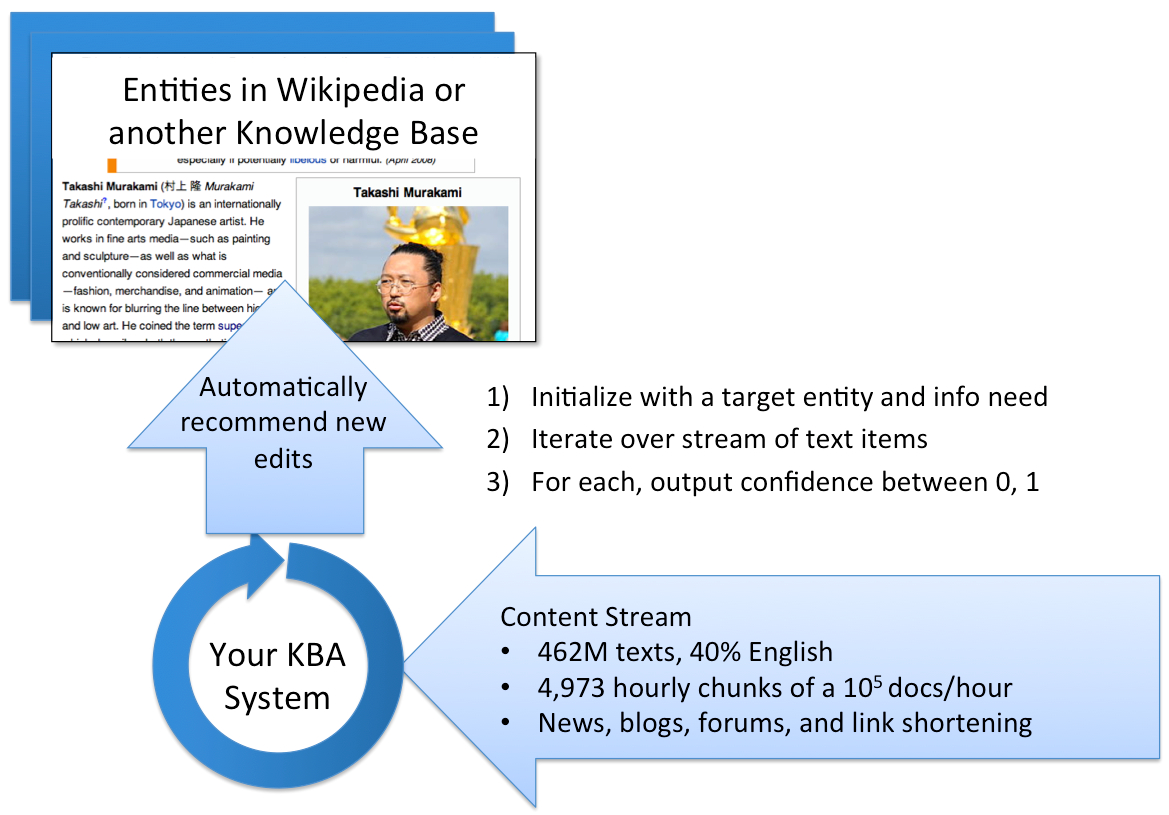
KBA seeks to help humans expand knowledge bases like Wikipedia by automatically recommending edits based on incoming content streams. This open evaluation measures an automatic system's ability to filter a large stream of text for new knowledge about entities.